رباتهای وب و نقش آنها در اینترنت
امروزه بخش زیادی از ترافیک اینترنت توسط رباتها (Web Crawlers / Bots) ایجاد میشود. این رباتها برنامههایی خودکار هستند که بهجای کاربر واقعی، به سایتها درخواست ارسال میکنند. هر ربات بسته به هدفی که دارد، رفتار متفاوتی روی وبسایتها نشان میدهد.
۱. Googlebot
-
توسعهدهنده: گوگل
-
کاربرد: خزنده اصلی موتور جستجوی گوگل برای ایندکس کردن صفحات وب.
-
ویژگیها: بهصورت مستمر صفحات را بررسی میکند تا تغییرات محتوایی به سرعت در نتایج جستجو بهروزرسانی شوند.
Googlebot خزنده اصلی گوگل است که صفحات وب را بررسی کرده و آنها را برای موتور جستجو ایندکس میکند. وظیفه آن جمعآوری اطلاعات از سایتها، دنبال کردن لینکها و بهروزرسانی نتایج جستجو است. وجود این ربات برای نمایش سایت در نتایج گوگل ضروری است.
۲. Facebookexternalhit
این ربات مربوط به فیسبوک یا اینستاگرام است. وقتی لینکی از یک وبسایت در فیسبوک یا اینستاگرام به اشتراک گذاشته میشود، facebookexternalhit وارد سایت شده و اطلاعاتی مثل عنوان، توضیحات و تصویر (از طریق Open Graph Tags) را جمعآوری میکند تا پیشنمایش لینک در facebook یا instagram به درستی نمایش داده شود.
۳. Bingbot
-
توسعهدهنده: مایکروسافت
-
کاربرد: خزنده موتور جستجوی Bing.
-
ویژگیها: رفتار مشابه با Googlebot دارد و برای نمایش سایت در نتایج Bing ضروری است.
۴. YandexBot
-
توسعهدهنده: یاندکس (موتور جستجوی روسیه)
-
کاربرد: ایندکس و رتبهبندی صفحات وب در یاندکس.
-
ویژگیها: در کشورهای روسیه و اروپای شرقی اهمیت دارد.
۵. Baiduspider
-
توسعهدهنده: موتور جستجوی بایدو (چین)
-
کاربرد: ایندکس سایتها در موتور جستجوی چینی baidu.
-
ویژگیها: برای وبسایتهایی که قصد ورود به بازار چین دارند اهمیت حیاتی دارد.
۶. DuckDuckBot
-
توسعهدهنده: DuckDuckGo
-
کاربرد: جمعآوری دادهها برای موتور جستجویی که بر حفظ حریم خصوصی تمرکز دارد.
-
ویژگیها: برخلاف گوگل، اطلاعات شخصی کاربران را ذخیره نمیکند.
۷. Slurp Bot
-
توسعهدهنده: Yahoo
-
کاربرد: ایندکس محتوا برای سرویسهای جستجوی یاهو.
-
ویژگیها: امروزه کمتر فعال است اما همچنان در برخی سرویسهای یاهو استفاده میشود.
۸. Twitterbot
-
توسعهدهنده: توییتر (X کنونی)
-
کاربرد: مشابه Facebookexternalhit، برای نمایش پیشنمایش لینکها در توییتر یا ایکس استفاده میشود.
۹. LinkedInBot
-
توسعهدهنده: لینکدین
-
کاربرد: جمعآوری متادیتا از صفحات وب برای نمایش لینکها در شبکه اجتماعی لینکدین.
۱۰. Applebot
-
توسعهدهنده: اپل
-
کاربرد: رباتی که برای بهبود سرویس Siri و Spotlight اپل استفاده میشود.
-
ویژگیها: روی محتوای وب تمرکز دارد تا کاربران اپل بتوانند نتایج دقیقتری دریافت کنند.
۱۱. سایر رباتها
علاوه بر اینها، رباتهای خیلی خیلی زیاد دیگری نیز فعالیت دارند. همچنین برخی رباتها برای اهداف تبلیغاتی، مانیتورینگ یا حتی حملات اسپم یا ddos طراحی میشوند.
مسدود کردن رباتها با htaccess
یکی از سادهترین روشها برای مسدود کردن رباتها در سرورهای لینوکس، استفاده از فایل .htaccess و بررسی مقدار User-Agent است. با این کار میتوانید مشخص کنید کدوم رباتها اجازه دسترسی به سایت داشته باشن و کدام رباتها بلاک شوند.
برای بلاک کردن useragent مورد نظر کدهای زیر را در htaccess قرار دهید:
RewriteEngine on
# Start Abuse Agent Blocking
RewriteCond %{HTTP_USER_AGENT} "Barkrowler" [NC,OR]
RewriteCond %{HTTP_USER_AGENT} "SemrushBot" [NC,OR]
RewriteCond %{HTTP_USER_AGENT} "meta-externalagent" [NC]
# End Abuse Agent Blocking
RewriteRule ^.* - [F,L]
توضیح:
-
RewriteCond %{HTTP_USER_AGENT} ...→ بررسی User-Agent. -
[NC]→ یعنی case-insensitive (بزرگ و کوچک بودن حروف مهم نیست). -
[OR]→ برای شرطهای پشتسرهم (هرکدام برقرار باشد). توجه داشته باشید در خط مربوط به آخرین دستور RewriteCond نباید از OR استفاده کنید. -
RewriteRule .* - [F,L]→ هر درخواستی از این رباتها بیاید، خطای 403 Forbidden برگردانده شود.
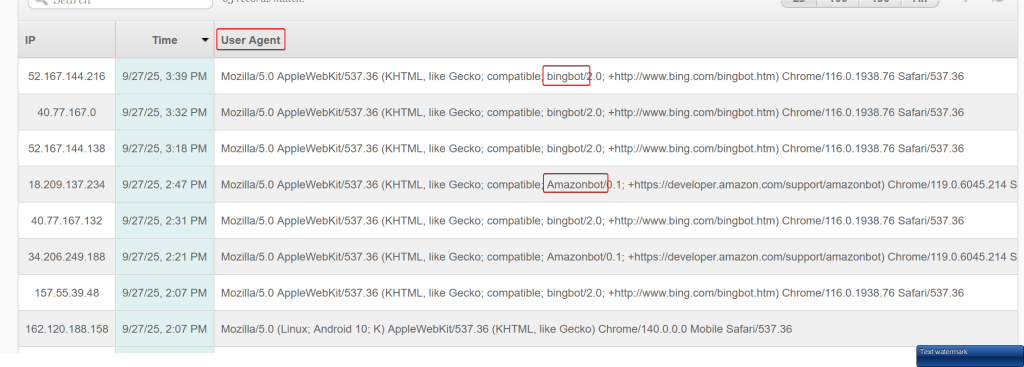
پیدا کردن user agent درخواست های ارسالی به سمت سایت:
در سی پنل در بخش Visitors یا بخش Raw Access میتوانید لیست درخواست هایی که برای سایت ارسال میشوند را ببینید و User Agent درخواست ها را مشاهده کنید.
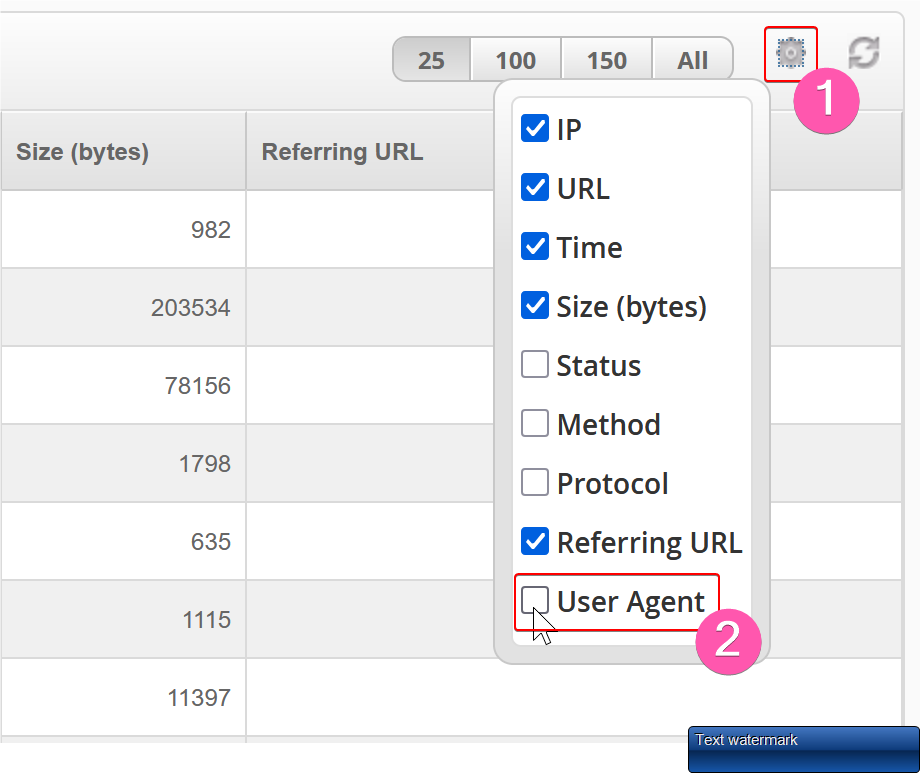
اگر ستون user agent را نمی بینید با کلیک روی دکمه بالای صفحه میتوانید انرا فعال کنید:
Shortlink for this post: https://blog.talahost.com/?p=2770